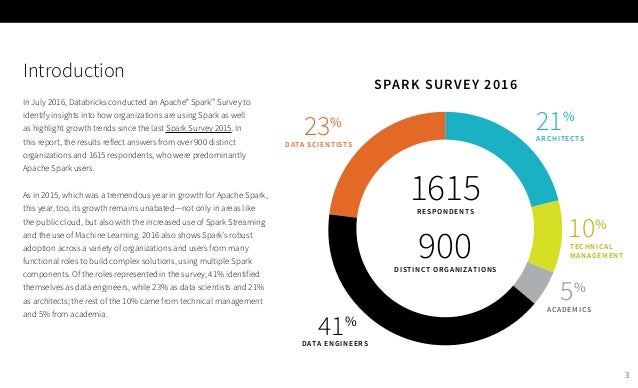
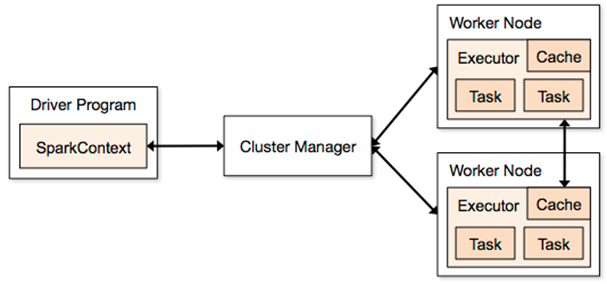
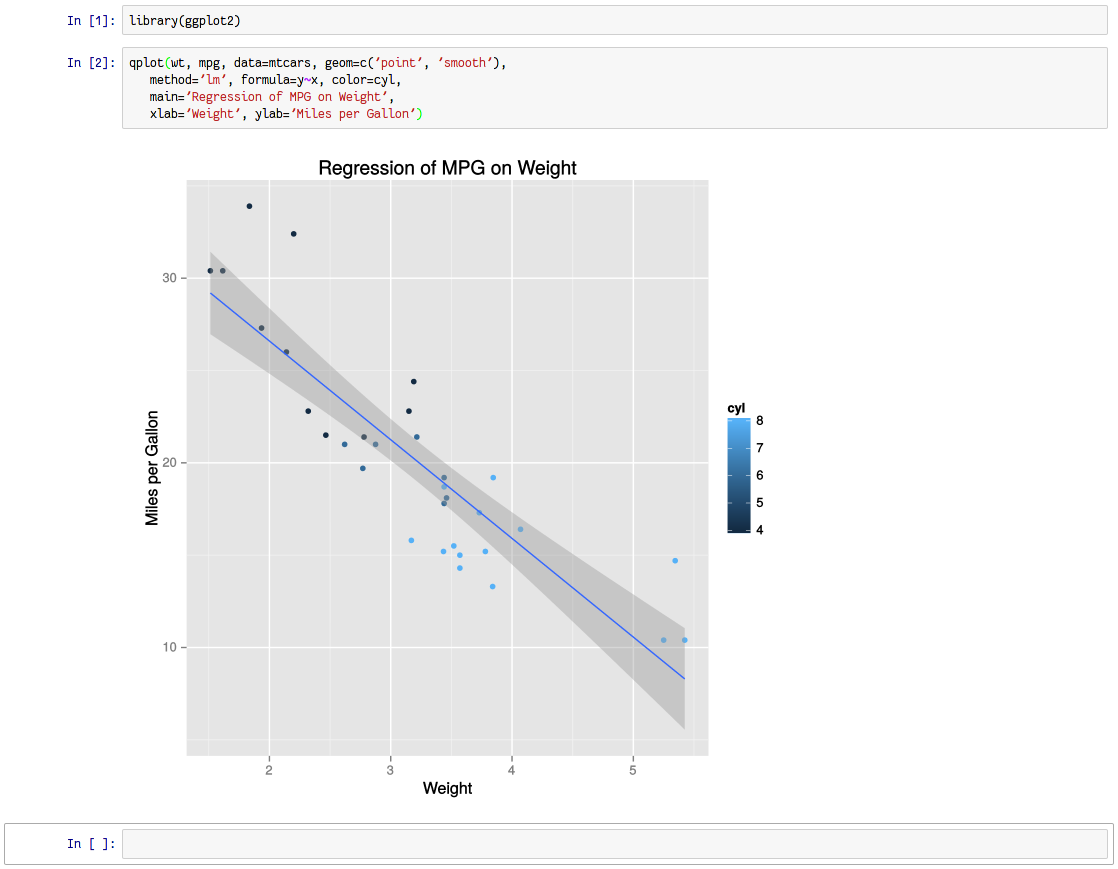
1일차 : 2018-08-18 토요일
소설 쓰는 딥러닝 - 조용래
- POZA Labs + 연세대학교 김우정
- 딥러닝을 사용할 때 어려운 점
- 한국어 특성 중 교착어
- 장기 의존성 학습 (이 전 문장에서 나왔던 내용이 후로도 영향을 미침)
- 학습 속도
- 과정
- Tokenizer
- KoNLPy, soynlp 사용해 보았음
- customized dictionary를 만들어서 판타지 소설 지명을 추가함
- Transformer (Encoder-Decoder Framework)
- 참고 : Attention is all you need 논문을 기본으로 학습해 봄
- Attention As Alignment
- Attention As dictionary
- Multi-Head Attention
- 결과적으로 소스 문장에 기반한 문장을 생성하는 것이 가능함
- 장점 - RNN계열에 비해서 약 30배 정도 병렬적인 학습속도 개선을 얻을 수 있음
- 단점 - 소스 문장이 길어질수록 제곱에 비례해서 속도가 느려짐
- Memory network
- Question Answer 모델을 사용
- Memory를 만들듯이, 문장을 찾고자 하는 정보에 대한 결과로 사용함
- Generator & Rank
- BEAM search
- 여러 개의 후보 문장을 끝까지 만들어 보고, 괜찮은 문장을 평가해서 최종적으로 선택하는 방식 (단어 하나하나를 선택하는 방식이 아님)
- Ranking
- 지금까지의 문장과 다른 새로운 문장에 높은 점수를 줌
- ETC - Tensorflow vs PyTorch
- Static Graph vs Dynamic Graph
- Good for Prototyping vs Good for Debugging
- 결과
- Input : 사용자가 5개의 문장을 시작으로 선택함
- Output : 10개의 후보 문장을 만들면 하나하나, 그 중에서 적절한 문장을 선택함
- KT 인공지능 소설 공모전에 출품한 작품
인생은 짧아요, 엑셀 대신 파이썬 by 이승준
- https://www.slideshare.net/plusjune/ss-109967905
- RPA(Robot Process Automation)에 있어서 파이썬은 너무 좋다
- 엑셀시트 사용
- OpenPyXL, xlwings, XlsxWriter
- 대부분의 데이터 처리는 pandas / matplotlib로 쉽게 대체가 가능하다.
- 크롤링 / 쪽지, 이메일 보내기는 Selenium + BeautifulSoup로 간단하게 가능
- 액티브X 인증서 기반도 opencv등을 응용한 pyautogui등을 사용하면 충분히 클릭 같은 부분도 자동화가 가능하니 참고하도록 하자.
- 보고서 생성 같은 부분도 Jinja2를 사용하면 쉽게 markdown을 바로 보고서 문서로 바꾸는 것도 가능함.
- 이메일 자동화는 smtplib / MIMEMultipart 참고
- 메신저 봇 자동화 python-telegram-bot
- Robot Framework 는 이러한 모든 사무자동화 문제들을 통합적인 Framework로서 제공해 주는 툴임
- 브라우저 자동화
- 엑셀 자동화
- 데스크탑 자동화
- 운영체제
- 원격 접근, 제어
- 엑셀시트 사용
2일차 : 2018-08-19 일요일
추천 시스템을 위한 어플리케이션 서버 개발 후기 @ kakao by 김광섭
- Slides
- 서비스 아키텍쳐
- 서비스 -> mySQL 서비스 스키마 -> 추천 엔진 데이터
- 서비스 -> mySQL 서비스 스키마 -> 추천 엔진 데이터
- 개발에서의 고민들
- Python2 vs python3
- =tornado vs Sanic의 문제였다.
- 결국은 Python3로 바꿨음
- Sanic의 문법이 훨씬 가독성이 높게 나온다.
- 성능에 있어서도 tornado대비 약 2.1배 빠른 응답속도 (uvloop 덕택)
- 데이터베이스 프로파일링
- 최적화의 끝은 결국 네트워크 IO가 Bottle Neck이 되더라.
- MongoDB의 aggregate기능으로 여러 연산 중복 실행 가능
- 그 중 $filter 사용 결과가 우월했음.
- 반면 groupby의 경우는 DB에서 너무 느리기도 했다.
- 이 경우는 App 레벨에서 처리하는 게 더 빨랐음.
- 데이터 슈퍼 노드 문제
- Sharding을 할 때, DB가 이상하게 죽는 문제가 있었음
- 원인은 공통으로 사용되는 리소스가 있어서 부하가 1번 샤드에 몰리는 문제
- 내부 DB 서비스를 사용했기 떄문에 해결이 가능했음
- gunicorn 사용의 이점
- WSGI 특성으로의 장점이 매우 컸음
- App 레벨에서 프로세스를 껐다 키는 것처럼 간단하게 앱 관리가 편했음
- 수치 연산
- 기본 라이브러리가 느리다고 의심되는 부분이 있으면 꼭 C로 짜서 대체하는 걸 고려해보자.
- 수치 연산에 일반적으로 Numpy, Pandas 등을 사용하기는 하는데, 벡터 연산, Matrix 연산 에서는 고려해 보자.
- 딥러닝을 적용하는 데 있어서도 Softmax 결과들을 종합하는 연산 부분을 C로 짜서 Cython으로 했더니 굉장히 개선된 경우가 있었음
- Python2 vs python3
땀내를 줄이는 Data Preprocessing & Feature Engineering by 박조은
- Intro : Data cleansing에서 필요한 여러가지 작업에서 수월한 툴 이야기
- plotnine - R의 ggplot을 그대로 사용 가능함
Ready, Get set, Go by 김영건
- Slides
- 컨퍼런스 행사에서의 스프린트 (=오픈소스를 같이 집중적으로 짜 보는 행사)
- 스프린트의 역사는 오픈소스의 역사화 함께 함 : pycon보다 오래됨
- 실제 오픈소스에서의 스프린트, 특히 큰 오픈소스의 스프린트는 정말 좋다.
- 굉장히 즐겁게 다 같이 개발을 하는 경험을 쌓을 수 있는 시간입니다.
- 놀라운 점
- 스프린트의 최고 장점은 아무래도 메인테이너와 오랜 시간 같이 있을 수 있다는 것
- 스프린트의 최고 장점은 아무래도 메인테이너와 오랜 시간 같이 있을 수 있다는 것
- 현재 진행되고 있는 스프린트
- pyData Sprint
- DjangoCon Sprint
- Mozilla Doc Sprint
- 공개SW개발자센터 컨트리뷰톤
- Worldwide pandas sprint 2018
- 2018-03-18 하루 동안 246 PR이 올라옴
- 스프린트에 대한 팁
- 왠만하면 뒷풀이는 참석하자 (스프린트는 친해지는 자리)
- 메인테이너가 있는 스프린트에 참석하는 것이 좋긴 함
- 10명 정도 사이즈가 좋은 것 같습니다. (도와주는 사람 많으면 20명까지도 가능)
- 10월에도 추가로 스프린트를 할 예정이니, 같이 했으면 좋겠습니다.
- 다양한 전 세계의 파이콘에서 다양한 스프린트를 하니 그 부분도 참고하세요
법률 네트워크 분석: 30년간의 변화 by 김재윤
- 법률과 프로그래밍은 굉장히 비슷한 점이 많다.
- 법률에서의 에러
- 인용오류 발생 = 404 Error
- 시행예정법률 개정 오류 = 버전 혼동
- 최근 에러 증가, 법률의 복잡성 증대 때문?
- 글자 1700만자, 법률간 인용 매년 7% 증가
- Law as a network
- 법률 = Node, 법률간 인용 = Edge
- Law 법률 네트워크의 복잡성은 계속 늘어나고 있음
- 입법주의가 잘 유지되고 있는가가 의심된다.
- 현재 우리나라 법률에서는 Power law, Truncated Power Law 분포가 등장하고 있다.
- 즉, ‘자연법칙’의 패턴이 입법에 나타나고 있다. 이는 과거의 법률이 현재의 법률에 지속적인 제약을 준다는 것을 뜻한다.
- 입법의 통제 가능성과 가독성에 대해서 걱정할 필요
- US Code (=USC, 미국법률)은 Log-normal분포를 보인다.
- 알파로우 스터디, 싸이버스
- 다음 시즌도 계속됩니다. 참가해 주세요!
- 다음 시즌도 계속됩니다. 참가해 주세요!