- 2017-06-27, Spark Day 2017
Spark bootcamp
- 강사 : 임상배(오라클) / 권혁진(오라클)
- Cover : Spark Core, Spark SQL, Spark Streaming
Spark 잡다한 이야기들
- 2014년 이후로 Spark가 hadoop보다 관심도가 높아짐
- Hadoop에 비해서 약 30배 정도의 성능을 보여줌
Spark는 전 세계적으로 1000개 이상의 조직에서 사용중
- Data Scientist / Data Engineer의 전폭적인 사용
- BI, Data warehousing, Log processing 등에 쓰임
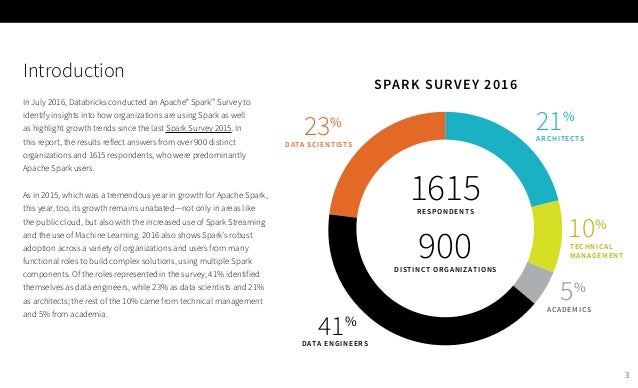
Spark 활용 사례
- Baidu : 1000대, 20,000코어, 100TB 램
- Spark + Tachyon
-> 50X Acceleration from ML in Hadoop - Toyota
- 고객관리 / 소셜미디어 분석
- 그외
- 고객 행동기반 Segment : Netflix, ING, etc…
- 게임 내 어뷰저 모니터링 및 검출 : LINE,
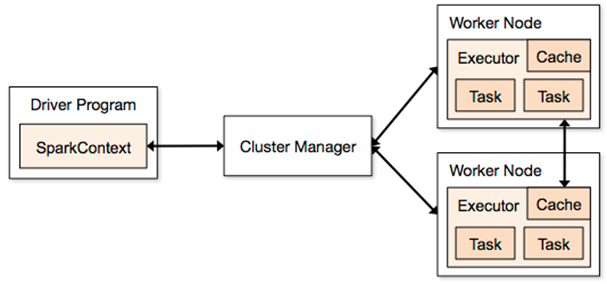
Architecture
- Driver Program : 전체 자원 관리자
- Cluster Manager : task 관리자 성격 (Mater = Cluster Manager)
- Worker Node : 실제 task 동작 단위 (Slave = Worker)
RDD : Spark Operation Core
- Keywords
- Fault Recovery Results
- Lineage : 계산 시 유실된 파티션을 기록하여 재수행할 수 있게 함
- Lazy execution : 최적의 cost로 자원을 배치하여 수행 가능
- Data sharing in RAM memory
Spark Hands On Session
- virtualBox로 진행
- sparkedu/sparkedu
- vm 아이디 비번 raj_ops/raj_ops이나 admin/admin 시도해보세요~ 쉘의 경우에는 root/hadoop.
Spark SQL
- Spark SQL + Catalyst(SQL optimizer) + DataSet(DataFrame)
- DataFrame 같은 경우는 누가 써도 고른 성능이 나오는 편
- DataSet Demo
Using Apache Spark 2.0 to Analyze the City of San Francisco’s Open Data
Deep Learning on Spark
TensorflowOnSpark
- 가장 범용적
- Tensorflow 최근 코드를 제대로 따라오지 못하는 듯
CaffeOnSpark
- 이미지에 굉장히 강함
- 요즘은 많이 죽었음 : Yahoo가 운영을 포기
TensorFrame
- 요즘 괜찮음 : Databricks 주도로 개발중
- Native embedding of Tensorflow
DL4J
- Java를 기반으로 Spark에서 Native하게 사용가능
- 아직은 사용자 층이 얇아서 대응이 느림
BigDL
- Intel의 주도 개발, 서버 CPU활용에 초점을 맞춰 개발됨
- GPU보다도 CPU만 가지고도 높은 성능의 Deep Learning 학습 가능
- 모델이 큰 용량인 빅데이터에 대해서 적용 수월
- 그럼에도 불구하고 GPU가 비슷한 성능의 CPU보다 딥러닝에 있어서 30배 이상 빠르다. (Pascal Titan X vs Dual Xeon E5)
Spark on Kubernetes
- Kubernetes = K8s
- Open source Automation Framework
- Why K8s?
: Cluster Deployment에 관리가 좋음 - Spark on K8s : Cluster 관리 시 추천
- Mater / nodes 구조로 되어 있음
튜토리얼 세션
컨퍼런스 세션
- Spark 의 과거, 현재, 미래 (이문수)
- Machine Learning & Deep Learnig With Spark (이상훈)
- Spark-zeppelin (김태준)
- Spark on Kubernetes (정유선)